Concepts
This document explains the key concepts, architectural patterns, and terminology used in the MSR (Multi-Session Replay) module.
Core Architecture
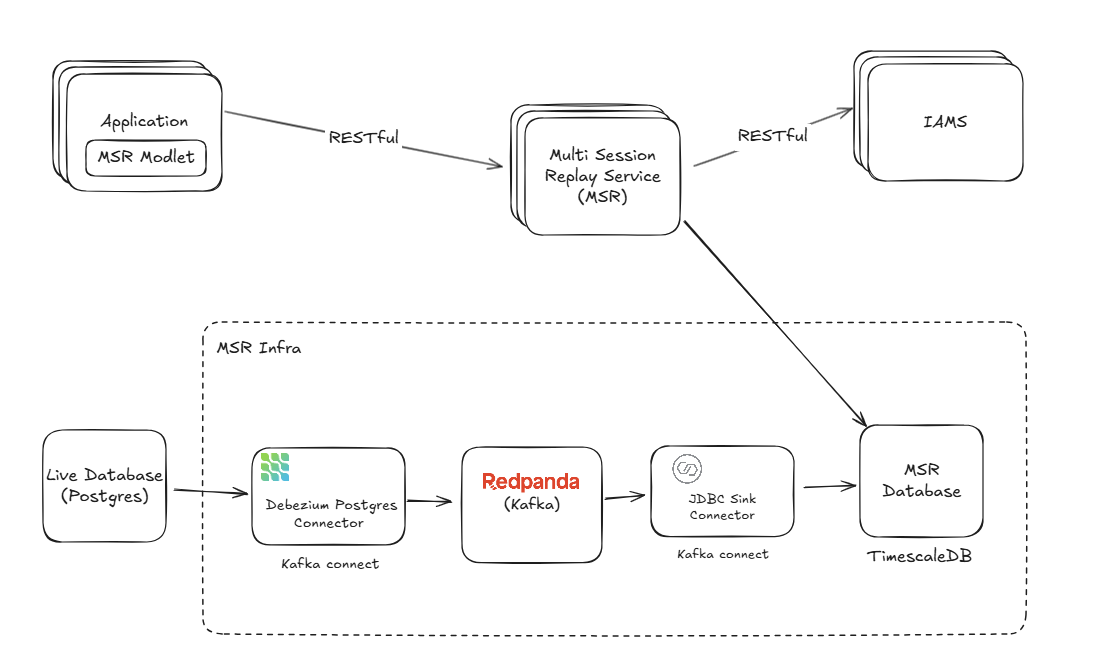
The MSR module is built around a Change Data Capture (CDC) architecture that allows developers to record database table states and replay them at any point in time. This approach enables detailed After Action Reviews (AARs) by providing complete historical visibility into system state changes.
Change Data Capture (CDC)
Change Data Capture is the foundational pattern used by MSR to track historical state changes. Unlike Event Sourcing, CDC is minimally invasive and can be retrofitted onto existing systems without architectural changes.
Key Characteristics
- Non-invasive: CDC acts as an external observer, monitoring database transaction logs
- Source of truth: The primary database remains the definitive source for current state
- Historical accuracy: Provides an unassailable record of what data changed and when
- Broad compatibility: Can be applied to existing state-based systems
Session Management
Session
A session in MSR represents a replay instance where users can view system state at a specific point in time. Sessions are managed to balance system resources and user experience.
Session Lifecycle
- Creation: Users request a new session to replay historical data
- Active: Session is actively being used for data replay
- Inactive: Session is idle but still consuming resources
- Terminated: Session is closed and resources are freed
In the sample session management page implementation, you will only see "active" and "inactive" states, these do not directly correspond to backend states but are simplified for user understanding.
Session Limits
The system enforces limits on concurrent sessions:
- MAX_ACTIVE_SESSIONS: Global limit on total active sessions
And limits on the historical range that can be replayed:
- MAX_PLAYBACK_RANGE: Maximum time range (in days) that day is available for replay
Data Storage and Management
TimescaleDB Integration
MSR leverages TimescaleDB as its time-series database backend, providing:
- Hypertables: Automatic partitioning of data into time-based chunks
- Performance: Optimized for high-volume time-series data ingestion
- SQL Compatibility: Full PostgreSQL feature set with time-series enhancements
Data Structure
CDC Events Table
Stores the raw stream of change events captured by Debezium:
CREATE TABLE msr.cdc_event (
entity_id TEXT,
entity_state JSONB,
op CHAR(1), -- 'c', 'r', 'u', 'd'
event_timestamp TIMESTAMPTZ,
table_name TEXT -- Source table identifier (schema.table_name)
);
Entity Snapshots (Rotating Materialized Views)
MSR uses a custom rotating materialized view system that provides baseline states for optimized state reconstruction. This in-house solution replaces TimescaleDB continuous aggregates with zero-downtime snapshot updates:
Architecture:
- Two materialized views: One holds the current snapshot, the other is used for building the new snapshot
- Rotation mechanism: After refreshing the inactive view, a pointer atomically switches which view is active
- Application view: A normal view that always points to the currently active materialized view
-- Two materialized snapshot views for zero-downtime rotation
CREATE TABLE msr.earliest_snapshot_a (
entity_id TEXT,
table_name TEXT,
entity_state JSONB,
op TEXT,
event_timestamp TIMESTAMPTZ,
PRIMARY KEY (entity_id, table_name)
);
CREATE TABLE msr.earliest_snapshot_b (
LIKE msr.earliest_snapshot_a INCLUDING ALL
);
-- Pointer tracks which materialized view is currently active
CREATE TABLE msr.snapshot_pointer (
id INTEGER PRIMARY KEY DEFAULT 1 CHECK (id = 1),
current_snapshot CHAR(1) DEFAULT 'A' CHECK (current_snapshot IN ('A', 'B')),
last_refresh TIMESTAMPTZ DEFAULT NOW(),
cutoff_time TIMESTAMPTZ DEFAULT NOW()
);
-- Application view - always points to the active materialized view
CREATE VIEW msr.current_earliest_snapshot AS
SELECT s.entity_id, s.table_name, s.entity_state, s.op, s.event_timestamp
FROM msr.snapshot_pointer p
CROSS JOIN LATERAL (
SELECT * FROM msr.earliest_snapshot_a WHERE p.current_snapshot = 'A'
UNION ALL
SELECT * FROM msr.earliest_snapshot_b WHERE p.current_snapshot = 'B'
) s;
Benefits:
- Zero-downtime updates: Applications continue reading from the active view while the inactive one is refreshed
- Atomic switching: Pointer update is instantaneous, ensuring consistent snapshots
- Optimal performance: Materialized views provide fast baseline state access for reconstruction
State Reconstruction
Point-in-Time Reconstruction
The core capability of MSR is reconstructing the complete system state at any historical timestamp. This process combines:
- Latest Snapshot: Most recent baseline before target time
- Delta Events: All changes between snapshot and target time
- State Merging: Combining baseline with deltas for final state
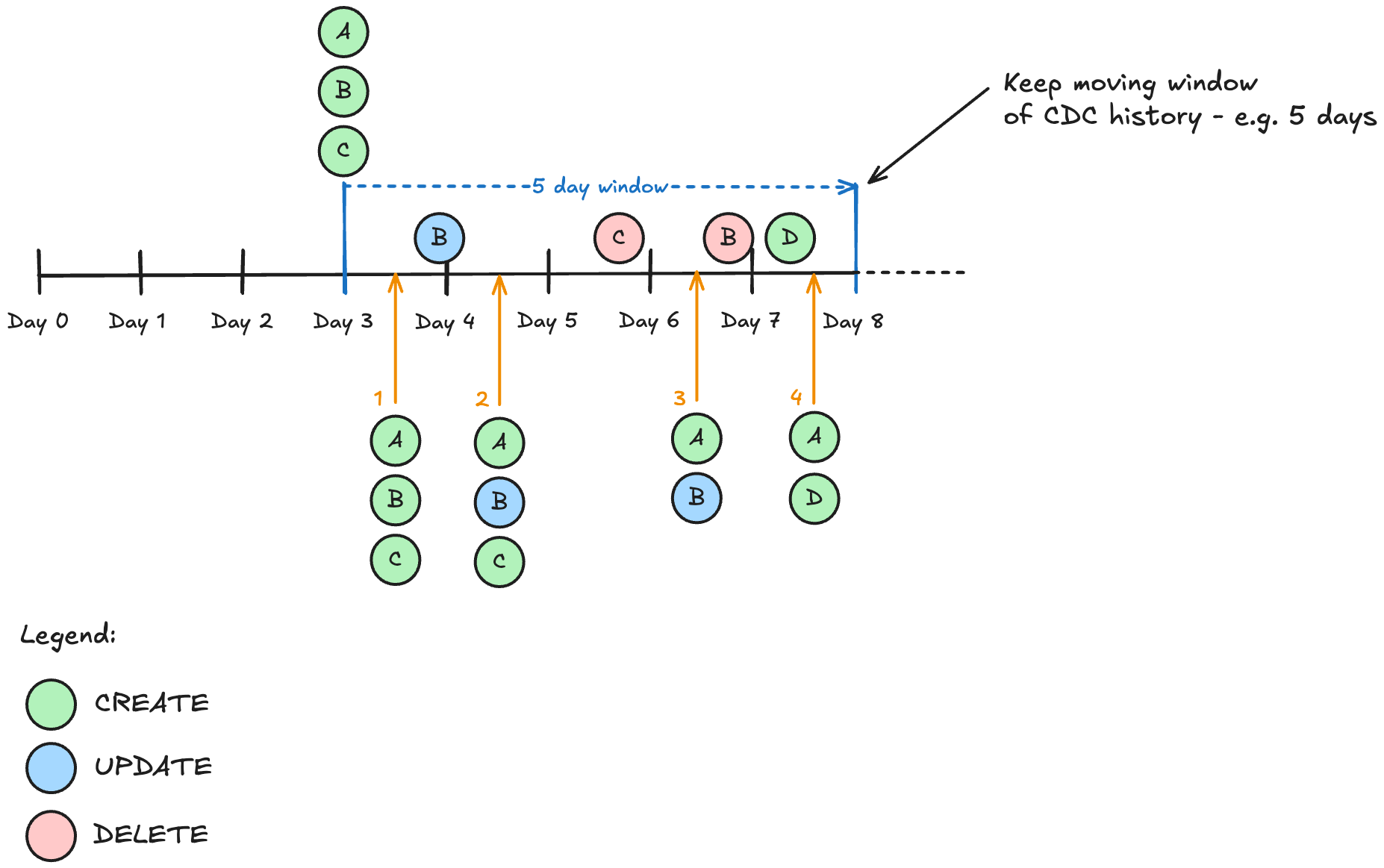
Reconstruction Algorithm
The state reconstruction follows this logic:
- Find Latest Snapshot: Locate the most recent snapshot before target timestamp
- Collect Delta Events: Gather all change events since the snapshot
- Apply Changes: Use
DISTINCT ONto get the latest state for each entity - Filter Deletions: Remove entities marked as deleted (
op = 'd')
Data Lifecycle Management
Automated CDC Cleanup Service
MSR includes an automated cleanup service that maintains optimal system performance by:
- Snapshot Refresh: Refreshes the inactive materialized view, then atomically switches the pointer to make it active
- Old Data Removal: Removes CDC events older than the configured retention period
- Scheduled Execution: Runs on a configurable cron schedule (default: daily at 3am)
- Bootstrap Support: Automatically creates initial snapshots on first deployment
The cleanup service can be disabled in development environments using the CLEANUP_SERVICE_ENABLED environment variable.
Retention Policies
MSR implements automated data lifecycle management:
- Configurable Retention: Set via
DATA_RETENTION_CRON_EXPRESSIONconfiguration - Playback Range: Limited by
MAX_PLAYBACK_RANGE(default: 7 days) - Earliest Valid Timestamp: Optional hard limit via
EARLIEST_VALID_TIMESTAMP - Hybrid Validation: Combines configuration and automatic snapshot detection
Data Availability Boundaries
MSR enforces data availability through multiple mechanisms:
- MAX_PLAYBACK_RANGE: Limits how far back users can replay (in days)
- EARLIEST_VALID_TIMESTAMP: Optional absolute earliest timestamp for replay
- Snapshot Cutoff: Automatically determined based on available snapshot data
The most restrictive boundary is enforced, ensuring data integrity and system performance.
Compression
TimescaleDB's native compression provides:
- Storage Savings: Often >90% reduction in storage requirements
- Query Performance: Improved analytical query performance
- Automatic Management: Policy-driven compression of older data
Frontend Architecture
Stateless Backend, Stateful Frontend
MSR employs a unique architecture where:
- Backend: Stateless services that reconstruct state on-demand
- Frontend: Maintains session state and manages user interactions
- Benefits: Improved scalability, simplified session management, enhanced user experience
Web Worker Integration
For performance optimization, MSR uses Web Workers to:
- Offload Processing: Move heavy state management off the main UI thread
- Maintain Responsiveness: Keep user interface smooth during data processing
- Handle Large States: Manage memory-intensive operations efficiently
Integration Components
Debezium Source Connector
Monitors source databases and captures change events:
- PostgreSQL Connector: Reads from transaction logs using
pgoutput - Kafka Integration: Streams events to Kafka topics
- Transformation: Applies Single Message Transforms (SMT) for data formatting
JDBC Sink Connector
Processes Kafka events and stores them in MSR database:
- Batch Processing: Optimized batch inserts for performance
- Data Transformation: Formats events for TimescaleDB storage
- Error Handling: Robust retry mechanisms and error recovery
Entity Types and Operations
Entity ID
The entity_id uniquely identifies each tracked entity, typically corresponding to a primary key in the source table.
It is important to note that this ID is expected to be unique within the context of a source table across all time.
However, it is not globally unique across different tables or databases.
When mapping your tables, you might have a composite key in the source table; in such cases, concatenate the key fields
into a single string to form the entity_id.
Entity Operations
MSR tracks four types of database operations:
c(Create): New entity insertionr(Read): Initial state capture (from snapshots)u(Update): Entity modificationd(Delete): Entity removal
Entity State Format
Entities are stored as JSONB objects and can basically represent any table structure - configure the source connector
to map your desired tables' columns into the JSONB entity_state field.